
Integrative clustering for heterogeneous datasets.
The goal of context-dependendent clustering is to identify clusters in a set of related datasets. Clusternomics identifies both local clusters that exist at the level of individual datasets, and global clusters that appear across the datasets.
A typical application of the method is the task of cancer subtyping, where we analyse tumour samples. The individual datasets (contexts) are then various features of the tumour samples, such as gene expression data, DNA methylation measurements, miRNA expression etc. The assumption is that we have several measurements of different types describing the same set tumours. Each of the measurements then describes the tumour in a different context.
The clusternomics algorithm identifies
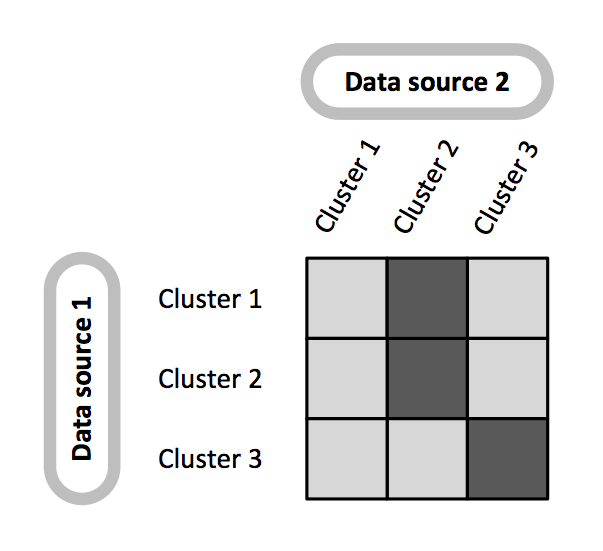
The following diagram illustrates the distinction. When we look at
the data sets individually, context 1 contains three clusters and
context 2 contains two clusters. These clusters correspond to the local
clusters in the clusternomics package. On the global level,
there are three distinct clusters that are only revealed when we look at
the combination of local assignments within individual datasets.
Use the devtools package to get the current version of
the package:
devtools::install_github("evelinag/clusternomics")See the package vignette for usage on a simulated dataset.
The package was tested using datasets originally downloaded from TCGA.