


En el artículo anterior de la serie de bases de datos vía la World Wide Web vimos los componentes de los que iba a formar parte nuestro sistema de acceso a la base de datos y las ventajas de utilizar GNU/Linux como sistema de desarrollo para nuestro proyecto. En este artículo vamos a seguir en la línea dictada por el anterior determinando el componente que nos falta para desarrollar el sistema, en particular, el lenguaje a través del cual vamos a programar el acceso la base de datos; veremos varias alternativas y nos decantaremos (por varias razones) por una de ellas.
También vamos a hacer una breve introducción a la aplicación que vamos a realizar, definiremos el esquema entidad-relación y la conversión a tablas de la misma.
Quedará para el siguiente artículo el diseño del interfaz en sí y su implementación con herramientas de generación automática.
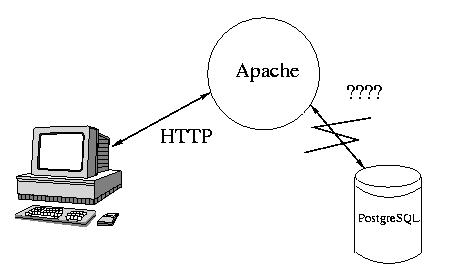
El uso de Apache y PostgreSQL nos da la arquitectura necesaria para instalar un sistema de acceso a base de datos vía WWW, pero como se puede dar cuenta el lector, aún falta un componente intermedio żquién actúa de unión entre el servidor de WWW y el servidor de la Base de Datos? (ver Figura 1).
****************** FIGURA 1*****************************
Es el diseñador el que ha de tomar la decisión de qué se puede implementar entre la base de datos, y el servidor, aunque en realidad puede no ser en absoluto necesario que estos se comuniquen, como ahora veremos. Hay dos posibles soluciones a este problema, por un lado se puede mantener la arquitectura cliente/servidor a través del protocolo HTTP, y por otro se puede romper esta arquitectura y separar los dos servidores de forma que el cliente utilice un método de acceso distinto para cada uno.
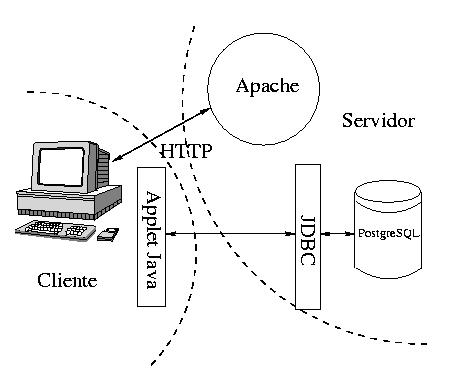
En este segundo caso (presentado en la Figura 3) el papel del servidor de WWW sería el de ofrecer la aplicación que permite al cliente se comunicarse con la base de datos. Esta aplicación estaría necesariamente programada en Java y se distribuiría como un applet dentro de una página HTML. Esta posibilidad no va a ser tratada dentro de esta serie ya que rompe el esquema que hemos pretendido introducir, el diseño de esta aplicación no sería con tecnologías estándar de la WWW (formularios, páginas, etc..) sino que sería realizada ad hoc para el problema particular al que nos enfrentamos. El interfaz gráfico se realizaría con los elementos proporcionados por el lenguaje Java (ya sea AWT o Swing), y la comunicación con la base de datos se haría a través del estándar JDBC.
******************** FIGURA 3 **************************
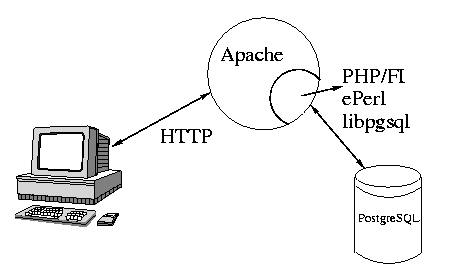
Para el primer caso (mostrado en la figura 2) tenemos varias posibilidades de comunicación entre el servidor y el sistema de base de datos, todas tienen en común el hecho de que nos van a permitir "introducir" la aplicación como elemento dentro de páginas HTML normales. Utilizando tags especiales podremos incorporar los elementos de programación de dichos lenguajes, que serán preprocesados antes de enviar la página al cliente. El cliente, por tanto, no será consciente de la existencia de una base de datos por debajo por que, por lo que a él respecta, los datos se devuelven de la misma forma de lo que está acostumbrada a ver cualquier persona que navega por la WWW. Para realizar la entrada de datos se utilizarán, pues, formularios como se definen en el estándar HTML, cuyos datos serán procesados dentro de la programación de las otras páginas.
******************** FIGURA 2 *************************
Tenemos varios métodos para hacer esto:
mod_perl. Se trata de un módulo para Apache que permite
introducir código Perl (Practical Extraction and Report
Language) en las páginas, de forma que se pueda obtener un
comportamiento dinámico. Asímismo, permite acelerar la ejecución de
CGI's ya escritos en Perl entre un 400% y un 2000%, ya que, al
introducirlo el Apache, desaparece la sobrecarga de inicialización del
intérprete (que siempre estará cargado). Usando Perl, junto con el
módulo DBI, podemos acceder, de forma transparente, a cualquier base de
datos. Este mecanismo se usa en múltiples servidores "activos" como
http://slashdot.org.
www-sql. Es un sencillo lenguaje para
introducir consultas SQL en páginas HTML, de forma que éstas sean
preprocesadas por un programa antes de enviar la página al
cliente. Actualmente sólo tiene soporte para las bases de datos
PostgreSQL y MySQL.Como se puede ver, las alternativas a la hora de hacer el diseño son abundantes y dependen, en gran medida, de la versatilidad que se quiera tener a la hora de implementar la aplicación. La alternativa de introducir Perl en las páginas es quizás la más versátil, ya que, una vez hecho se puede hacer uso de cualquiera de los módulos de Perl para casi cualquier función conocida (como por ejemplo conectarse a teléfonos móviles con WAP). El lenguaje PHP es también muy versátil, aunque no tanto como Perl, y se encuentra más limitado en el acceso a base de datos. Finalmente, www-sql es una librería mucho más específica, con un pseudo-lenguaje de programación mucho menos expresivo que los anteriores (tiene pocos sistemas de bucles y pocas funciones para manipular los datos).
Como quiera que en el proyecto que vamos a abordar no va a ser en
exceso complicado, vamos a elegir la alternativa que más sencilla va a
resultar de implementar, que será www-sql (en su versión para
PostgreSQL, es decir www-pgsql).
La instalación de este
lenguaje será bastante sencilla. Es necesario instalar la
aplicación en si, lo cual logramos instalando el paquete
www-pgsql en un sistema Debian GNU/Linux (para otras
distribuciones mirar el
listado 2).
************** LISTADO 2******************************+
Una vez hecho esto, se debería haber instalado un programa
(www-pgsql) en la localización de los CGI scripts de nuestro
sistema, este será generalmente /usr/lib/cgi-bin, aunque puede
modificarse por el fichero de configuración de Apache
srm.conf (en la línea ScriptAlias /cgi-bin/
/usr/lib/cgi-bin/). Lo que hace falta ahora es modificar tanto
nuestro servidor de WWW como nuestra base de datos para que sea
posible acceder a través de este sistema.
Para modificar a Apache, lo que vamos a hacer es modificar su fichero
de configuración srm.conf, para que todos los ficheros que
terminen en .pgsql sean procesados por el programa que acabamos
de instalar. Añadiendo lo siguiente:
# Para www-pgsql
AddHandler www-pgsql pgsql
Action www-pgsql /cgi-bin/www-pgsql
pgsql, enviará, antes de devolverlo al cliente
que lo ha pedido, este fichero a un programa (/cgi-bin/www-pgsql)
para que lo procese. Lo que será enviado al cliente será el resultado
de este programa. Para poder activar esta directiva es necesario que en el fichero htttp.conf esté definida la carga del módulo mime_module.
Para modificar el a gestor de la base de datos PostgreSQL y que
nuestro script pueda funcionar, es necesario editar los
ficheros de configuración para permitir varias cosas. Por un lado es
necesario habilitar la posibilidad de conectarse a la base de datos a
través de TCP/IP, de no estar habilitado sólo los clientes en la
máquina local podrían hacerlo. www-pgsql realiza
una conexión TCP/IP con el sistema de base de datos
(aunque esté instalado en el mismo servidor) y será
necesario habilitarlo, lo que lanzará al demonio de gestión de la misma
con la opción -i. Para ello modificamos el fichero de
configuración del gestor de la base de datos (en Debian GNU/Linux
/etc/postgres/postmaster.init) para añadir lo siguiente:
# Whether to allow connections through TCP/IP as well as through Unix
# sockets: yes/no.
# By default, for greater security, we do not allow TCP/IP access.
# This means that only users on this machine can access the database.
PGALLOWTCPIP=yes
A continuación es necesario modificar la configuración de la base de
datos para que permita acceso, sin clave, desde el ordenador local, por
defecto, en el fichero /var/postgres/data/pg_hba.conf. Se hace
esto sólo para conexiones a través de sockets en dominio UNIX (local)
y a través de localhost (dirección IP: 127.0.0.1), pero es
necesario habilitarlos para nuestra dirección IP. Suponiendo que
nuestra dirección IP fuera 192.168.1.1, modificaríamos el fichero para
que queda de la siguiente forma:
# Por defecto, permite cualquier cosa en sockets dominio UNIX y
localhost
local all trust
host all 127.0.0.1 255.255.255.255 trust
# Añadido para www-pgsql
host all 192.168.1.1 255.255.255.255 trust
Hay que tener cuidado, sin embargo, ya que esta configuración abre un posible agujero de seguridad en la base de datos. Si un usuario pone ficheros, al margen
de la aplicación que vamos a desarrollar aquí, con la extensión pgsql y
un cliente un cliente a ellos podrá poner arbitrariamente cualquier código
SQL dentro de páginas WWW que podrían descubrir información reservada de
la base de datos. No vamos a cubrir este aspecto en esta serie de artículos,
pero el usuario interesado podrá ver la forma de inhabilitar el acceso
a esta directiva (salvo en las zonas del servidor que le interesen) en
la documentación del servidor Apache.
De esta forma tendríamos la siguiente configuración (mostrada en la figura 4):
.pgsql la enviará al programa www-pgsql
para que la procese.www-pgsql procesará las directivas de
conexión a la base de datos (más adelante se verá cómo) y las enviará
al gestor de base de datos de PostgreSQL (postmaster).En realidad algunos de estos cambios (así como la creación de un usuario
para acceder a la base de datos como se verá más adelante) son necesarios
porque
www-pgsql establece necesariamente conexiones a través de sockets
TCP/IP. Lo hace aunque la conexión se realice con el propio ordenador local
(con el que podría establecer
conexiones a través de sockets en el dominio UNIX). Es posible modificar
las fuentes del programa para cambiar esto,
pero supondremos que el usuario dispone del programa original sin ningún
tipo de modificaciones.
Vistas ya todas las herramientas que vamos a utilizar, vamos a ver ahora el problema concreto sobre el que se van a aplicar para demostrar su uso.
El proyecto que se va a abordar es la creación de una Asociación de Antiguos Alumnos en Internet, el objetivo es que, a través de un cliente universal (un navegador de la WWW) se pueda acceder a una base de datos de información de Antiguos Alumnos de una determinada organización (instituto, escuela o universidad). Desde el servidor debe ser posible que las personas den de alta su información personal y que puedan consultar la información de personas de la asociación a través de formularios creados al efecto.
Para asentar más el problema, vamos a indicar que el objetivo de dicha asociación va a ser el de poder mantener en contacto a personas independientemente de su situación personal actual (trabajo), de forma que una persona que esté buscando a otra que pertenezca a la asociación, pueda hacerlo de una forma rápida. De esta manera se pueden perpetuar los lazos de comunicación existentes entre las personas antes de abandonar la organización, pero trasladándolos a un nuevo medio (correo electrónico e Internet).
En primer lugar vamos a abordar la parte esencial de este proyecto, evidentemente, si se estuviera diseñando este proyecto se deberían plantear objetivos posteriores a éste, tales serían, por ejemplo, la creación de un tablón de anuncios para fomentar la comunicación entre asociados o la generación de una lista de correo para la comunicación hacia todos los asociados de una forma directa. Vamos a centrarnos, sin embargo en la primera parte del proyecto.
A la hora de concretar la base de datos que va a necesitar nuestro proyecto es necesario hacer uso de una serie de metodologías para poder convertir la idea que tenemos del mismo en tablas que vayan a ser almacenadas en la base de datos.
El paso del concepto abstracto que se tiene del proyecto a la concreción de los elementos físicos (tablas) que maneja una base de datos no es, ni mucho menos, un paso inmediato y ni siquiera lleva siempre a la misma solución. Perspectivas distintas y distintos objetivos en la aplicación llevarán a desarrollar distintas tablas.
Sin embargo es necesario partir de un diagrama concreto, conocido como de entidad-relación que nos permite concretar la "idea del mundo" de nuestra aplicación. El diseño de estos diagramas hace necesario conocer cierta teoría de las bases de datos y tener cierta experiencia en su manejo. No se va aquí a explicar los pasos dados hasta llegar a él sino que se va a explicar el elegido, y que se muestra en la figura 5:
********************** FIGURA 5 ****************************
Este diseño lo materializamos en cinco tablas que serán las creadas dentro de la base de datos, como veremos más abajo.
Una vez definido el esquema entidad relación vamos a crear la base de
datos en nuestro sistema de bases de datos. Primero, vamos a proceder a
crear dos usuarios para poder gestionar la base de datos, en primer
lugar el usuario alumni que será el "dueño" de la base de datos de
nuestro proyecto, y por otro lado un usuarioque será
utilizado para acceder a los datos. Para acceder a los datos podríamos
utilizar el usuario www-data, que es el usado por defecto por
el interfaz www-pgsql, pero es necesario tener en cuenta
a la hora de crearlo y otorgar permismos que es necesario encerrarlo
entre comillas (debido al uso del carácter '-' en el nombre).
También podemos utilizar, si nos es más conveniente, el usuario nobody,
los ejemplos aquí serán con éste último.
Es necesario crear el usuario 'alumni' dentro de
nuestro sistema, ya que, además de ser el que administre la
base de datos será también en su directorio de usuario
(/home/alumni/public_html) donde vamos a alojar sus páginas
(para que sean accesibles como http://miservidor/~alumni). Lo
haremos de la forma habitual (esto es, con adduser) aunque
convendría dejarlo, de momento con la contraseña bloqueada.
Para terminar con la asignación de privilegios
, tenemos que dar acceso a estos usuarios a la base de
datos. Para ello tenemos que "convertirnos" en usuario
postgres, que es el responsable de dar de alta usuarios dentro
del sistema de base de datos: haremos (como superusuario)
su - postgres y crearemos tanto los usuarios como la base de
datos que van a utilizar, que no será más que un directorio (dentro de
/var/postgres/data/base). Un ejemplo de la sesión la tenemos
en el
listado 1.
Conviene distinguir, llegados a este punto, que los usuarios de la base de datos no han de existir necesariamente como usuarios de nuestro sistema, ya que a la hora de conectar con ésta utilizaremos un nombre de usuario determinado. Sin embargo, por simplicidad, aquí se van a usar los mismos usuarios en nuestro sistema operativo y en el gestor de bases de datos.
********************** LISTADO 1 ***************************
Una vez creados los usuarios
podemos "convertirnos" en usuario alumni (con
su - alumni como superusuario) y
crear las tablas en la base de datos. Para ello nos conectaremos, bien
vía el interfaz de línea de comandos psql o mediante el
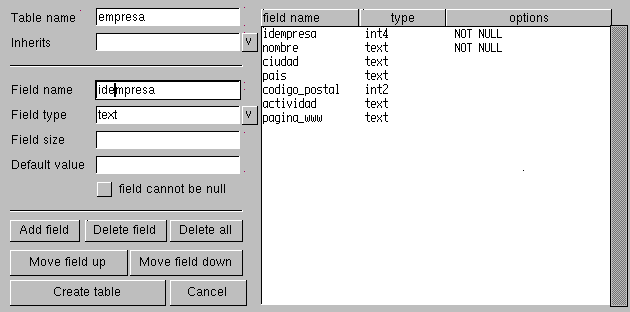
interfaz gráfico pgaccess (ver
Figura 6). Dado que el interfaz de texto es más ilustrativo
para el administrador es el que vamos a tratar aquí. Las órdenes SQL
para crear las tablas las tenemos en el
listado 3, para ejecutarlas, sólo tendremos que conectarnos a
la base de datos con psql alumni y ejecutarlas tal cual están
escritas allí (teniendo en cuenta sólo que tras mandar una orden SQL
hay que terminarla con el carácter ';').
********************** FIGURA 6 *******************************
********************* LISTADO 3 ****************************
Lo único que quedará tras crear las tablas es dar los permisos al usuario
nobody para que pueda acceder a éstas, lo hacemos con
la siguiente orden SQL: grant select on empresa, persona,
trabaja_en, usa_mail, usa_tfo to nobody. Una vez hecho esto
podríamos ver los permisos actuales con \z.
******************** FIGURA 7 ********************
En general, se pueden ver todas las órdenes que podemos enviar desde el
interfaz con \h y todas las órdenes administrativas
importantes (listar tablas, permisos, usuarios...) las vemos con
\?. Conviene acudir a la página de manual (man psql)
para conocer más sobre esta herramienta y a la documentación de
PostgreSQL (en Debian GNU/Linux se instala con el paquete
postgresql-doc) en /usr/doc/postgresql.
En este artículo se ha abordado el concepto de interfaz entre la base de datos y el servidor de WWW que es el que nos va a permitir, más adelante, enlazar, a través de la programación en páginas HTML, el interfaz del usuario con la base de datos. Ya hemos creado nuestra base de datos de ejemplo con el que trabajaremos en el siguiente artículo, lo único que nos falta es crear el interfaz vía WWW sobre el que se va a construir la aplicación final.
żQué actúa de unión entre el servidor y la base de datos?.
Por su sencillez, escogemos www-sql como alternativa.
Es necesario modificar Apache y PostgreSQL para preparar el interfaz.
Se va a abordar un ejemplo concreto.
La definición del esquema entidad relación es necesaria.
Se van a crear tablas en función del esquema.
Necesitamos crear la base de datos y los usuarios.
Las conexiones a la base de datos la hacemos como el usuario creado.
Psql es la manera más ilustrativa de modificar la base de datos.
Sólo falta crear el interfaz WWW.
postgres@fuego:~$ createuser alumni
Enter user's postgres ID or RETURN to use unix user ID: 1013 ->
Is user "alumni" allowed to create databases (y/n) y
Is user "alumni" a superuser? (y/n) n
createuser: alumno was successfully added
postgres@fuego:~$ createuser nobody
Enter user's postgres ID or RETURN to use unix user ID: 65534 ->
Is user "nobody" allowed to create databases (y/n) n
Is user "nobody" a superuser? (y/n) n
createuser: nobody was successfully added
Shall I create a database for "nobody" (y/n) n
don't forget to create a database for nobody
postgres@fuego:~$ createdb alumni
PIE LISTADO 1: Creación de los usuarios y de la base de datos
En general los lenguajes de interfaz a los sistemas de base de datos vía web podremos encontrarlos incorporados a nuestra distribución favorita, los paquetes relacionados en Debian GNU/Linux se indican a continuación, pero si no dispone de ellos en su distribución puede acudir a lista más abajo para recoger las fuentes e instalarlas en su sistema.
www-mysql: La interfaz a la base de datos MySQL.www-pgsql: La interfaz a la base de datos PostrgreSQL.libapache-mod-perl: El módulo de Perl para Apache,
puede ser utilizado para introducir código en páginas HTML junto con
libhtml-embperl-perl ó libhtml-ep-eperl.libapache-dbi-perl: Módulo que se puede usar junto con
un intérprete de Perl embebido para acceder transparentemente a bases
de datos utilizando Perl::DBI.libapache-asp-perl: el sistema ASP (Active Server
Pages) migrado a Apache y con soporte de Perl.libapache-dbilogger-perl: módulo de Apache para poder
seguir las transferencias a través de los accesos DBI.php3-cgi: ofrece un ejecutable independiente que se
puede comportar como un CGI para procesar páginas, y usar
conjuntamente con diversas ampliaciones para conectarse a distintas
bases de datos: php3-cgi-msql, php3-cgi-mysql, y
php3-cgi-pgsql.php3: módulos para Apache de PHP, se puede utilizar
conjuntamente con php3-mysql, php3-pgsql y
php3-msql.
PIE LISTADO 2: Información de los lenguajes de interfaz WWW-BD
create table empresa
( idempresa int not null,
nombre text not null,
ciudad text,
calle text,
pais text,
codigo_postal int,
actividad text,
num_empleados int,
pagina_www text,
primary key (idempresa)
)
create table persona
( dni int not null,
nombre text,
apellidos text,
calle text,
ciudad text,
codigo_postal int,
pais text,
graduacion int,
ingreso int,
fecha_nacimiento date,
pagina_personal text,
primary key (dni)
)
create table trabaja_en
( dni int not null,
idempresa int not null,
puesto text,
departamento text,
primary key (dni, idempresa)
)
create table usa_mail
( dni int not null,
e_mail text not null,
primary key (dni, e_mail)
)
create table usa_tfo
( dni int not null,
telefono text not null,
primary key (dni, telefono)
)
PIE LISTADO 3: Tablas a crear en la base de datos
Dado que en este artículo tiene muchos listados y capturas quizás el texto no llegue, por sí sólo, a las cuatro páginas previstas, pero se considera fundamental incluir todas las gráficas ya que el texto tiene muchas referencias a ellos.
Caso de ser necesario el orden de preferencia es el que sigue: figura 6, figura 3, figura 1, figura 7, figura 2. El resto (capturas y listados) conviene no quitarles porque se perdería demasiada información.
El siguiente artículo quizás sea más largo de lo que he planteado pero aún no lo tengo decidido así que quizás me haga falta un artículo más para cerrar la serie. Cuando haya escrito el siguiente ya lo diré.